SMART PRACTICES
The authoritative guide to Lean software development

Brad Hipps
10-31-2023
As a methodology, Lean is pragmatic, flexible, and time-tested. So why hasn’t it swept software engineering the way Agile has? Part of it may be a not-invented-here bias. Lean originated with automotive manufacturing, long before software teams were a thing. Could something born from the challenges of building things out of atoms really work for a discipline concerned with building things out of bits?
Another reason could be the terms that buzz around Lean—”kanban”, “value streams”, “WIP”, “flow efficiency”… it all sounds a little jargon-heavy and probably complicated.
My personal vote for why Lean has lived in Agile’s shadow is its prescription for continuous improvement. Not the principle itself, of course—who says no to improvement? Rather, the measures that Lean prescribes have been, at least historically, much easier to surface from instrumented machinery on a factory floor than they are from the “invisible” work of software development. (Again: atoms versus bits.)
Whatever the reason, Lean has plenty to recommend it. Let’s examine the case.
Lean principles—and what they mean for software dev
Happily, the principles of Lean are as nicely summarized as anything in the Agile Manifesto. There are five:
Specify the value the customer wants.
Identify the value stream for each thing the customer wants, and eliminate the wasted steps in providing it.
Make the product flow continuously through the remaining value-added steps.
Introduce “pull” between all steps where continuous flow is impossible.
Measure & improve so that the number of steps and the amount of time needed to deliver value to the customer continuously falls.
Granted, we’ve got some robotic sounding jargon-speak in there. (Value stream? What the hell does it mean to “introduce pull”?) But that’s why we’re here. To translate the principles into language that makes sense for software teams.
Let’s take ‘em one by one…
Specify the value the customer wants
The phrasing is a tad awkward (”Specify the value”), but Lean is all about moving value into customer hands as quickly and efficiently as possible. “Value” is just that—anything that your customer wants. The emphasis is on prioritizing things that respond to actual customer demand.
To make this a little more concrete: in the software world, “the value” is commonly a feature. The work for that feature is usually made explicit, specified, in the form of an objective or epic. (Because “epic” carries certain tool/methodology associations, I’ll stick with the more neutral “objective”.)
“Build what your customers want” may sound too obvious to bear stating. But poking around in most backlogs, you’re bound to find lots and lots things that someone somewhere just thought sounded cool. The relation of these cool-sounding things to actual customer value is hopeful at best.
As product builders, what we want is a short list of objectives at any given time, stack ranked by priority. We’re not interested in a bottomless backlog packed with every theoretically bright idea we’ve ever had. Backlogs aren’t parking lots. We want to be a value-delivery machine, not an idea-generation machine.
Identify the value stream for each thing the customer wants, and eliminate the wasted steps in providing it.
As a term, “value stream” has a vague, big-vendor, enterprise-y sound. It’s enough to make anyone sleepy. But the idea and purpose of a value stream is simple:
Identify all the steps involved in moving a product feature from request to customer hands.
Get rid of the wasted steps. (There are probably more than you think.)
If you do the above, you are in fact “managing your value stream.” That is, you’re continually working to improve your end-to-end delivery process—your ”request-to-delivery,” or “order-to-cash,” or any other name it may go by.
How many organizations actually take the time to a) make explicit every step in bringing a feature to market and b) eliminate the wasteful steps? In my own experience, not many. When we join a company, we often just sort of inherit its structure, its departments, its macro processes. Do we really need a formal product requirement doc to justify every engineering investment? Who knows— that’s just how it’s done, and we’ve already built the team and formalized the processes to do it.
More commonly, a company’s value stream—the steps for bringing value to customers—simply accumulate steps over time. It’s like technical debt on the process side: steps and teams and inputs and gates that just build up and build up. After enough time, the whole edifice begins to feel untouchable.
In a conversation I had with Ram Bolaños, an Engineering manager at Tegus*,* he said he makes it a point in any new company to “start slow, and ask lots of questions. Why do we work the way we work? Why these specific processes? What’s the history behind them?” That’s the kind of ongoing scrutiny and rigor that “value stream management” requires. It’s a habit of keeping your processes, well… lean.
Make the product flow continuously through the remaining value-added steps.
For software engineers, this one’s natural. It’s easier for us to automate the flow of features between our value steps than it is for builders of physical products. In fact, this is what things like continuous delivery have been all about.
Which brings us to…
Introduce “pull” between all steps where continuous flow is impossible
There’s that mysterious phrase again— “Introduce pull”.
What’s the essential difference between a “push” and “pull” model of work? One prioritizes starting work; the other, finishing it.
In the pull model:
Ideas are created in response to actual customer demand, stack ranked in priority;
The topmost ideas are then pulled by engineering teams into the development cycle as they have capacity to work them.
In the push model:
A bunch of work is planned, based largely on assumptions that customers will want it. (Think of all those endless backlogs…)
That work is then assigned out (pushed) to development team members, after negotiations with those teams over how quickly the work can start.
In the pull model, what you really want to know is: How well do ideas move from start to finish? How long (i.e., cycle time) does it take on average to get these ideas prioritized and built? Where are the bottlenecks in our workflow, and how do we eliminate them?
In other words: how do we move value into customer hands, from request to delivery, as quickly and efficiently as possible?
If this sounds obvious, good. Although there are plenty of product and engineering organizations who nod at the above, but actually use the push model. Why? Likely because that approach gives the illusion of progress. The emphasis falls on starting work. All negotiations revolve around how quickly work can begin.
We all know the comfort of being able to confidently report, “Work has started on [X].” But it can be a false comfort, and set up false expectations. Just because work has started doesn’t mean it’s going to be finished any time soon. Still, in the moment, it sounds better than saying, “We haven’t started that yet.”
The pull model prioritizes finishing work. In the pull model, new work doesn’t begin until sufficient work has been finished and the team has capacity.
The pull model has a few key benefits:
It emphasizes throughput—actual work finished—instead of starting lots of stuff and declaring progress.
It empowers people (and their teams) to keep work moving. This is because the decision to begin new work rests with them, based on their capacity as measured by
WIP limit. Everyone becomes an owner of good flow.
There’s less management overhead. A manager’s job is concentrated on helping to relieve bottlenecks in flow and grooming the To Do queue, not on evaluating capacity or deciding who should take on what work. The team members take care of that themselves.
Measure & improve so that the number of steps and the amount of time needed to deliver value to the customer continuously falls.
Lean really shines in the pragmatism of its metrics. They’re right there in the principle: you want to continually reduce “the number of steps” and “the amount of time” needed to deliver value. Simple, straightforward, without any confusion over what matters and why.
The harder part is what I mentioned at the beginning: how do we bring these metrics to life for software teams? Handily, this is a big part of what Socratic does. So let’s break down what it looks like.
Flow efficiency
By continually evaluating and reducing “the number of steps” we’re trying to optimize flow efficiency—how well work moves from start to finish. An efficient engineering team is one whose work moves through the minimum number of steps, with a minimum of interruptions. Naturally, some interruption in flow is inevitable. You’re simply trying to keep time spent in any exception (i.e., non-flowing) states to a minimum.
Socratic automatically derives exceptions to flow efficiency based on the way work moves (or fails to move):
Rework is the backward movement of work, e.g. from a test phase back into a development phase;
Deprioritized represents work that was started, but then returned to a backlog phase, likely in favor of new, higher priority work;
Idle is any work that goes more than seven days with no movement or code activity;
We also track the time tasks spend as blocked.
For efficiency, we want to know how much of our total active work time is spent productively—that is, in a normal flowing state—versus time spent in any of the above exception states.
Assume an objective has absorbed a 100 total work days so far. If the time spent in nonproductive states is only 20 days, we probably feel pretty good—our efficiency, by this measure, is 80 percent. But if that number were 50 days, it would mean that half our total time so far has been eaten up by blocked or idled tasks, reworking tasks, or burning time on things that fell out of priority. Something is off.
Cycle time
The “amount of time needed to deliver value” is measured by cycle time. Put even more plainly, our speed: how long does it take us to deliver work, from start to finish?
Socratic determines the actual average time, measured in days elapsed, required to complete tasks and objectives. With our Trends capability, we can see how our cycle time is changing period over period. If we notice a significant upward change, our eyes go immediately to the diagnostic metrics included as a part of cycle time: notably merge time (derived automatically from git), efficiency (explained above), and phase time.
Phase time reflects how much time work spends in a given work phase (e.g. “To Do” “Doing” etc.)—the steps in your value stream. Below is a real example from our team. This shows the average time tasks spent in each engineering work phase in August, relative to the average time by phase over the last six months.
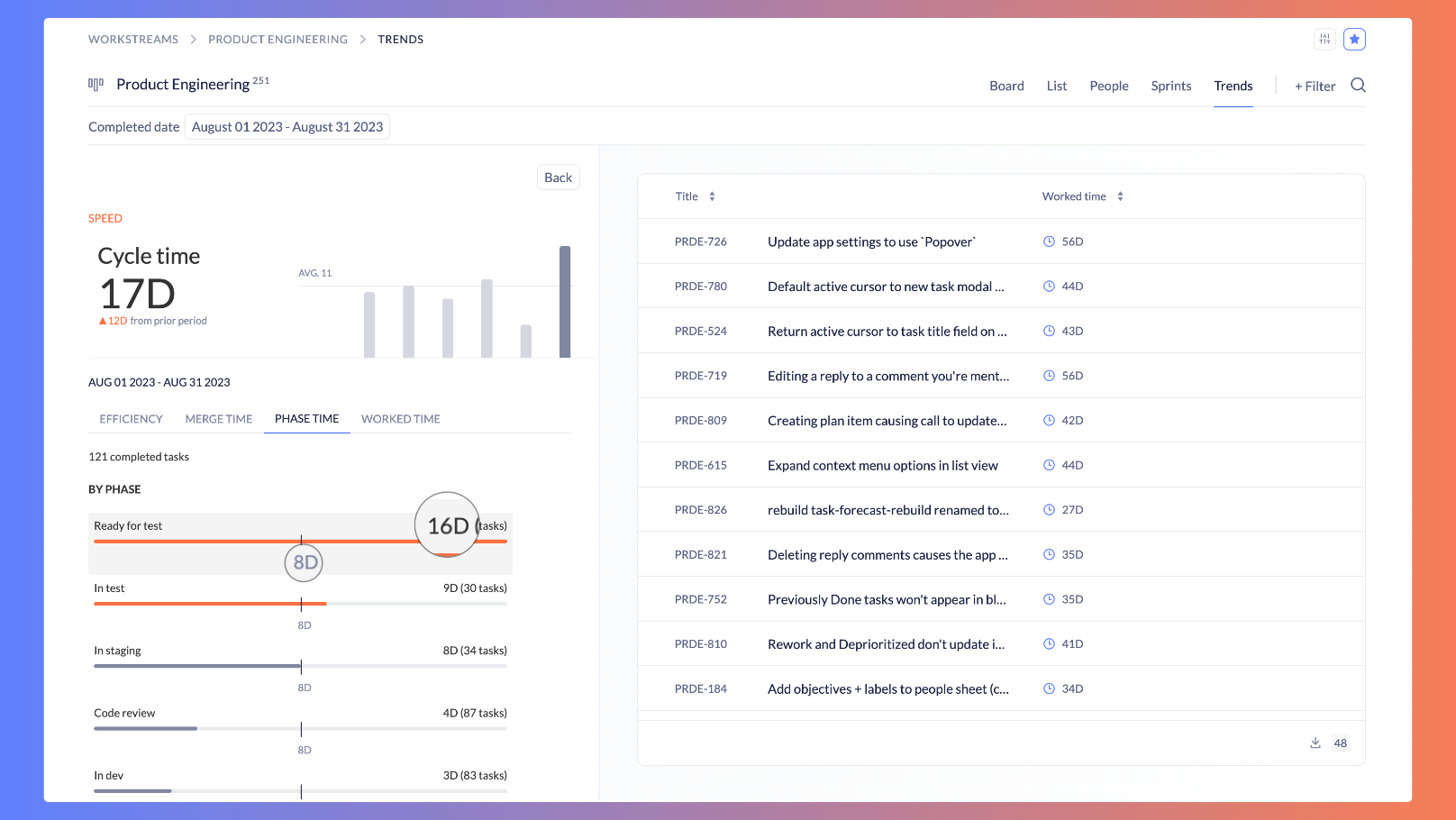
The bottleneck leaps off the screen: tasks spent an average of 16 days in our “Ready for test” work phase—double the monthly average for time in that phase!
“Ready for test” is a waiting phase. Meaning, engineering has completed its work and the tasks are waiting to be pulled into the test phase. By making these ‘wait’ phases explicit, we can use our data to better surface bottlenecks like this one. The solution? We need more QA capacity…
Throughput
Throughput goes back to Lean’s emphasis on finishing work, not starting it. Obviously, the starting variable for throughput is knowing how many objectives and tasks we completed in a given period. But that variable, by itself, is fairly meaningless. Is ten good? A hundred? A thousand?
What we're really interested in is the number of tasks we completed, relative to the number of new tasks raised. Ten tasks completed is actually a good number, if the number of new tasks raised over the same period was, say, seven. This tells us that delivery is outpacing demand.
But—can we really use tasks as the unit to measure throughput? These aren’t manufactured widgets, where each one is the same. Aren't there so many variations in task size and complexity, that you're essentially mixing apples and oranges and bicycles?
Paradoxically, the answer to both questions is Yes.
How? The law of large numbers (LLN). Over the course of enough tasks, the inevitable differences in complexity among them basically come out in the wash.
With flow efficiency, cycle time, and throughput, we have a neat encapsulation of what product and engineering teams should aim for: deliver a lot of customer value, well and at good speed. By these measures we can know—and show—that we’re doing our job.
Why lean on Lean?
Big picture, there are a number of things we like about Lean:
It emphasizes throughput
—actual work finished—instead of starting lots of stuff and declaring progress.
It empowers people
(and their teams) to keep work flowing. This is because the decision to begin new work rests with them, based on their
WIP limit. Everyone becomes an owner of good flow.
It helps keep people sane
by allowing them to focus on completing what’s on their plates before picking up more work.
It favors a pragmatic way of understanding—and showing—work health
, using actionable measures that anyone can understand: cycle time, throughput, and flow efficiency.
There’s less management overhead. A manager’s job is concentrated on helping to relieve bottlenecks in flow and grooming & prioritizing the backlog; team members are empowered to decide when to take on new work.
Never mind how long ago Lean principles were invented. They remain a timeless way for engineering teams to work.